
1. Numpy库
NumPy是高性能科学计算和数据分析 的基础包,是Python进行科学计算时所有高级工具的基础组件。
1.1 Ndarray
NumPy的ndarray是一个多维数组对象,主要由如下两个部分组成:
- 实际的数据。
- 描述这些数据的元数据。
1.1.1一元数组
1 | from numpy import * |
1.1.2 多维数组
1 | from numpy import * |
1.1.3 选取数组元素
1 | from numpy import * |
1.1.4 索引和切片
1 | from numpy import * |
1.2 Scipy
Scipy是基于NumPy的,提供了更多的科学计算功能,比如线性代数、优化、积分、插值、信号处理等。
1.2.1 文件读写
目前在国内Matlab仍然非常流行,Matlab使用的数据格式通常是
.mat文件。对此,Scipy.io包提供了可以导入导出.mat文件的接口,这样,Python和Matlab的协同工作就变得非常容易了。
1 | from scipy import io as spio |
1.2.2 线性代数运算
在Scipy中,线性代数运算使用的是scipy.linalg。
1 | # scipy.linalg.det()可用于计算矩阵的行列式 |
1.2.3 优化和拟合
求解最大值最小值之类的问题即为优化问题,在Scipy中,scipy.optimization提供了最小值、曲线拟合等算法。
1 | import numpy as np |
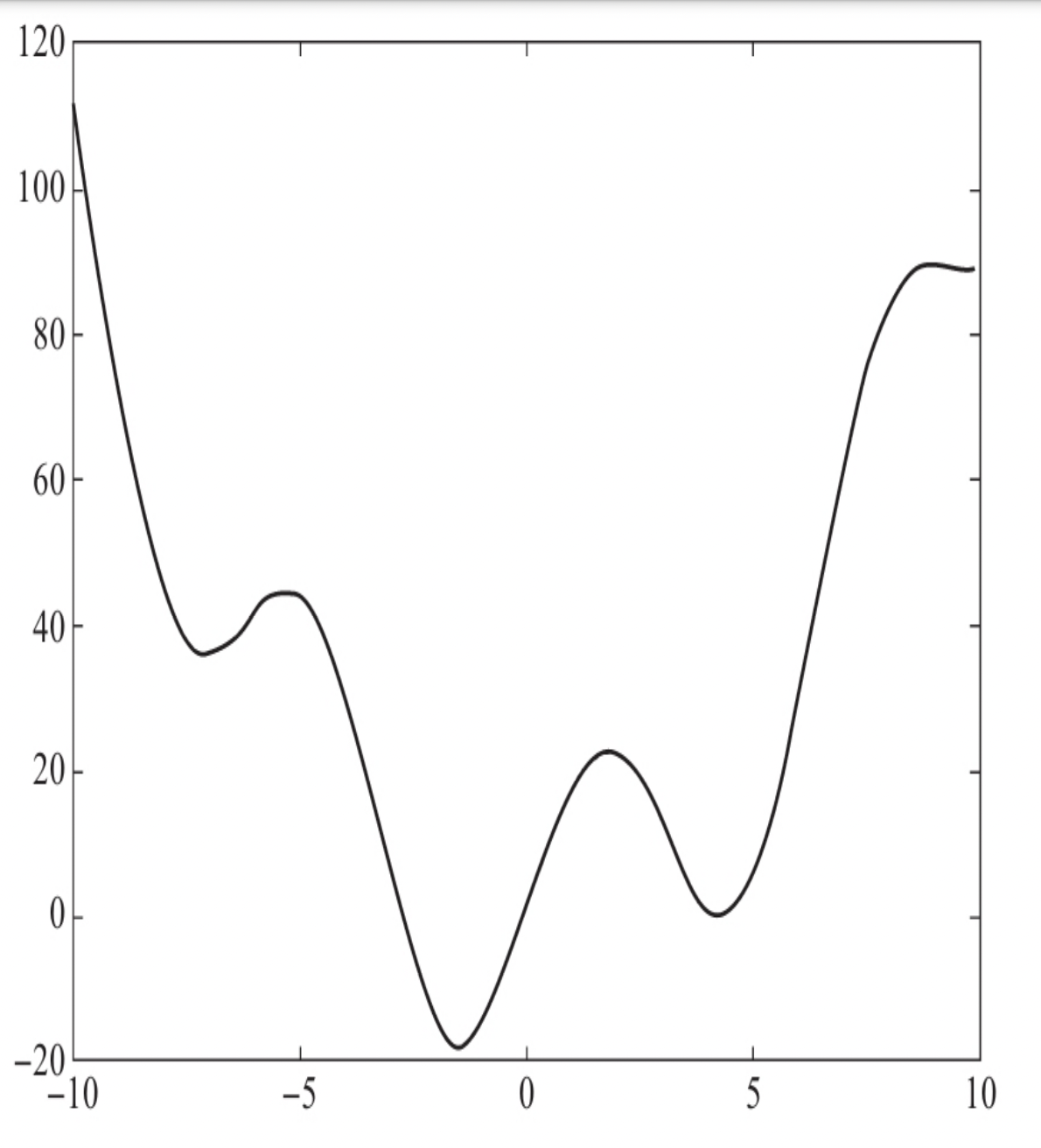
可以看到,对应的最小值的横坐标大约是-2。
我们可以用暴力穷举法来计算最小值
1 | grid=(-10,10,0.1) |
1.3 Pandas
Pandas具有NumPy的ndarray所不具有的很多功能,比如集成时间序列、按轴对齐数据、处理缺失数据等常用功能。Pandas最初是针对 金融分析而开发的,所以很适合用于量化投资。
Pandas包含两个主要的数据结构:
- Series
- DataFrame
1.3.1 DataFrame入门
DataFrame是一个表格型的数据结构。每列都可以是不同的数据类 型(数值、字符串、布尔值等)
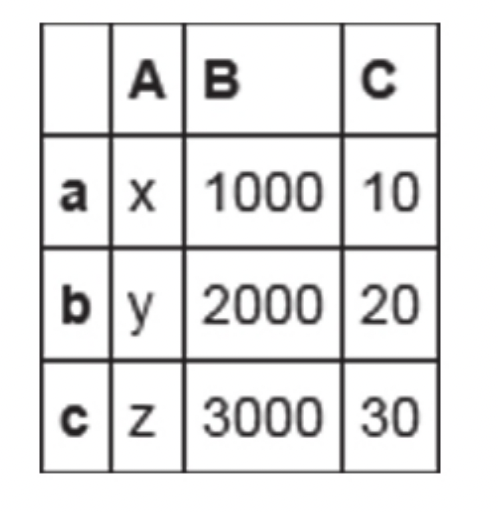
下面先来创建一个DataFrame,一种常用的方式是使用字典,这个 字典是由等长的list或者ndarray组成的
1 | data={'A':['x','y','z'],'B':[1000,2000,3000],'C':[10,20,30]} |
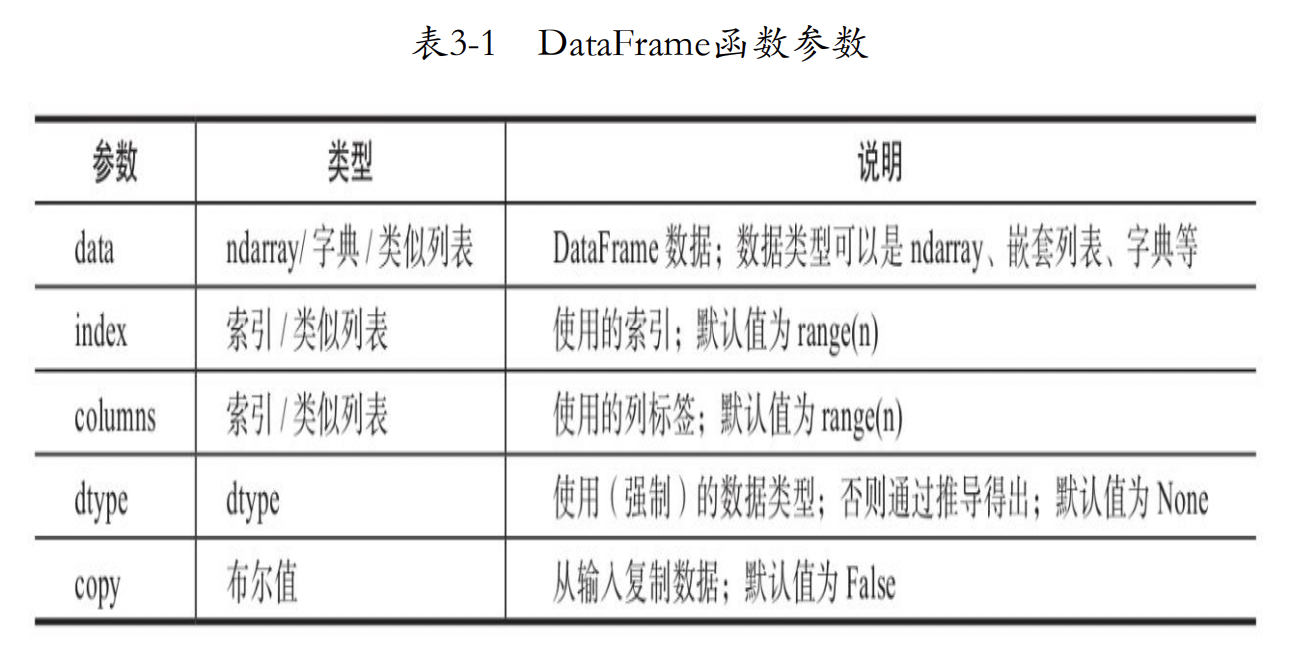
函数参数
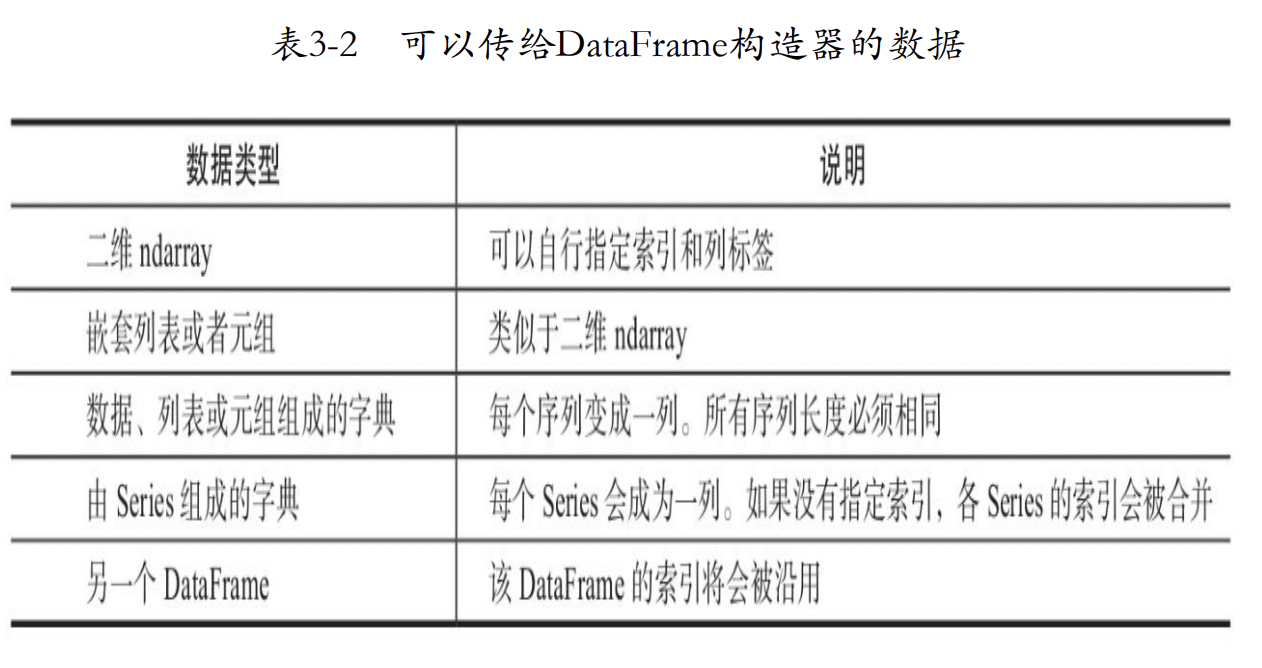
数据类型
2. 可视化分析
2.1 Matplotlib
2.1.1 散点图
在数据分析中,散点图是最常用的探索两个数据之间相关关系的 可视化图形。
1 | import numpy as np |
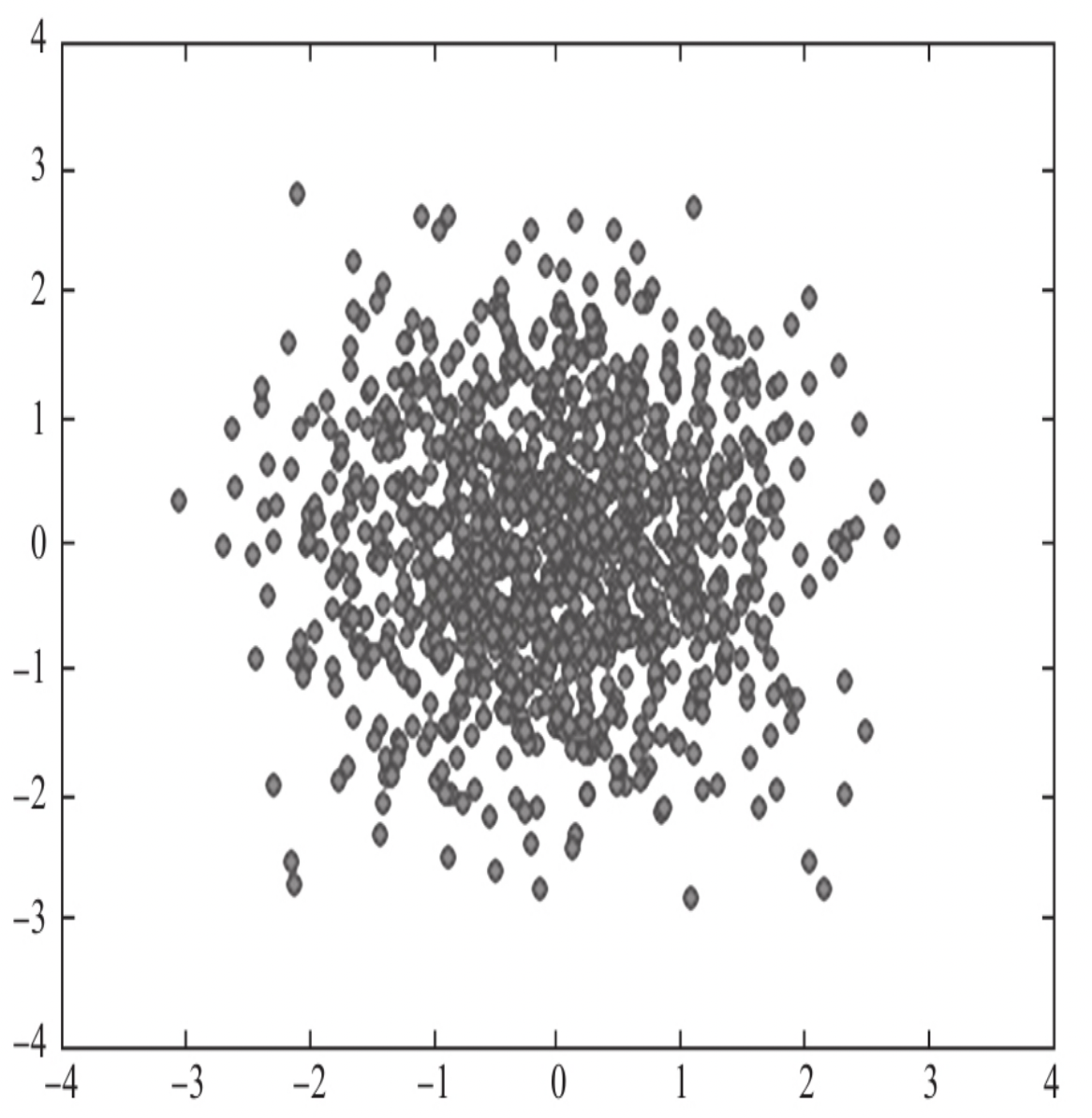
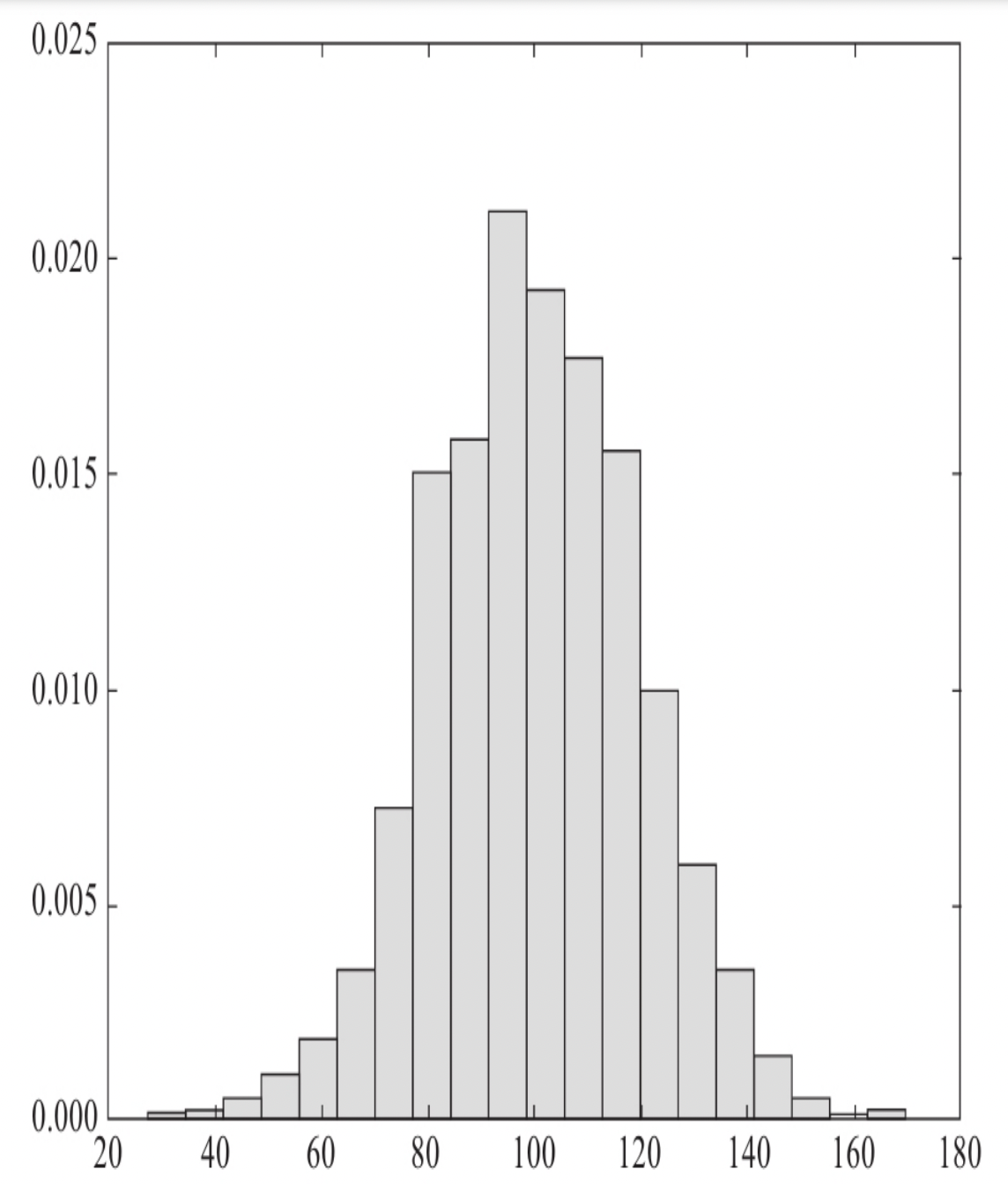
2.1.2 直方图
直方图主要用于研究数据的频率分布
1 | import numpy as np |
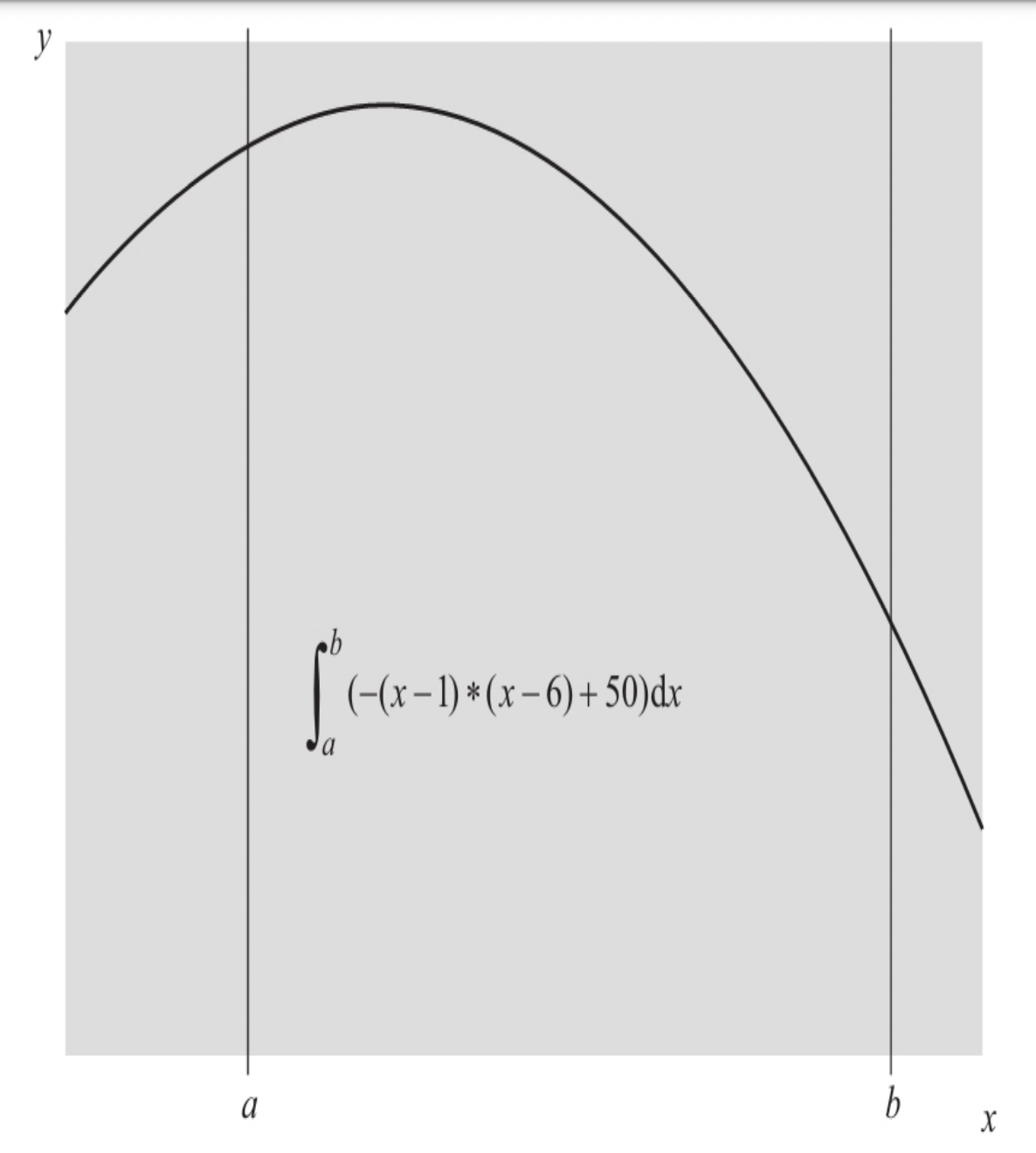
2.1.3 函数图
1 | import numpy as np |
2.1.4 Matplotlib和seaborn的中文乱码问题
可以用seaborn加代码的方式。
1 | from pylab import mpl |
2.2 Seaborn
在做统计相关的图形的 操作时,会比Matplotlib更容易上手一些,也更实用一些。在进行可视 化分析时,一般来说,笔者都会优先考虑使用seaborn。
1 | import seaborn as sns |
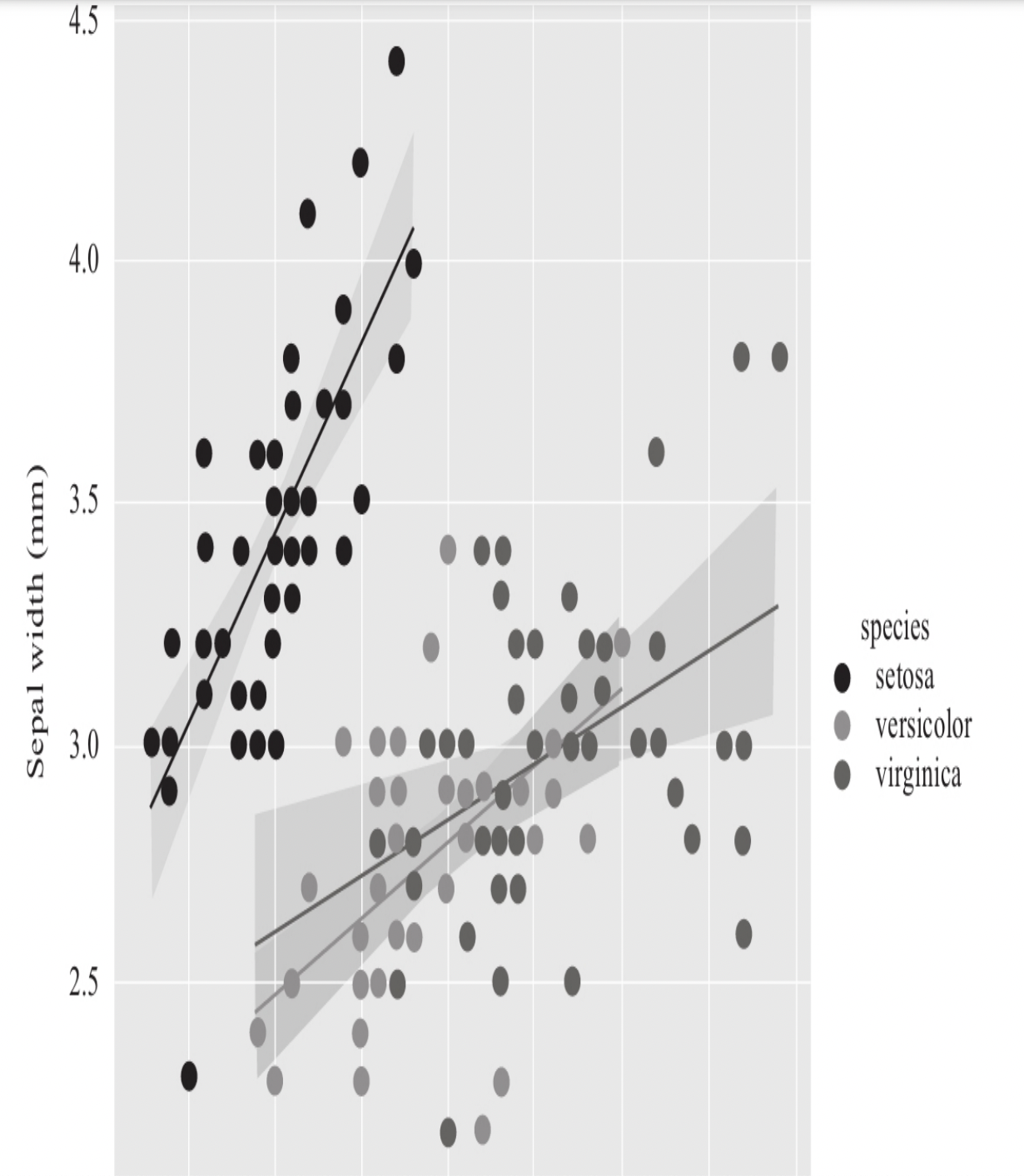
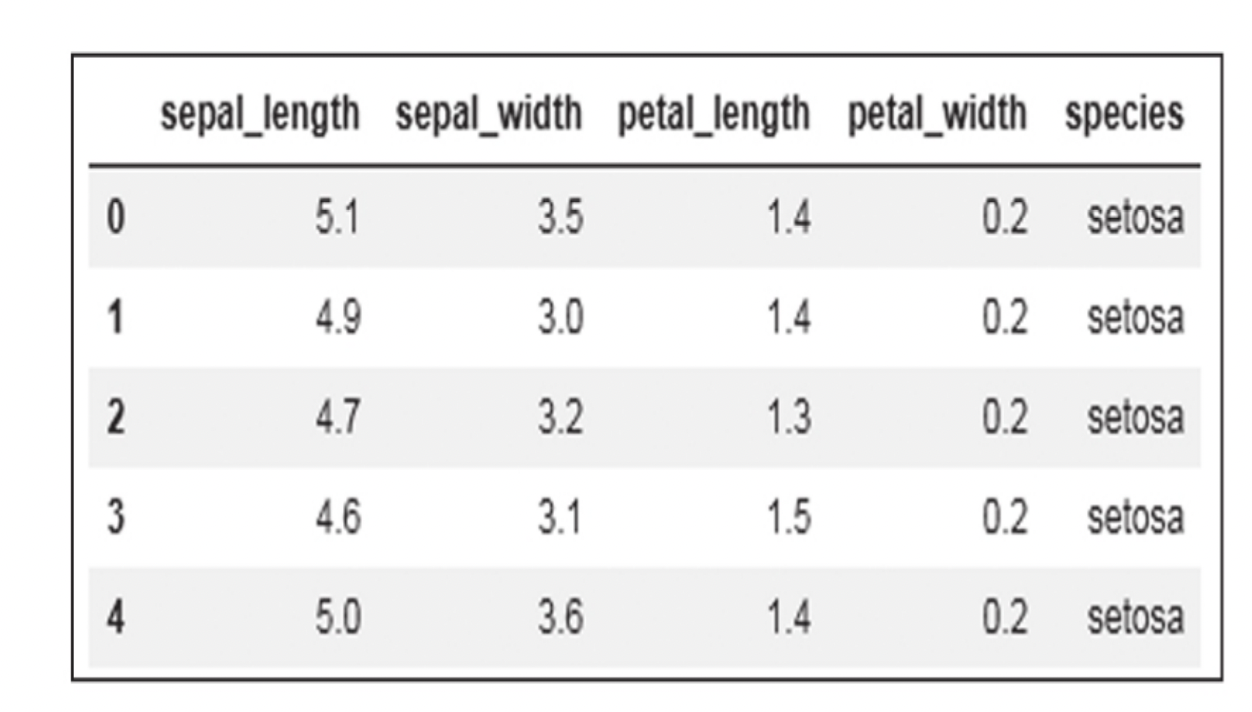
通过如下的命令来观察一下数据:
1 | iris.head() |
3. 统计基础
3.1 基本统计概念
3.1.1 随机数和分布
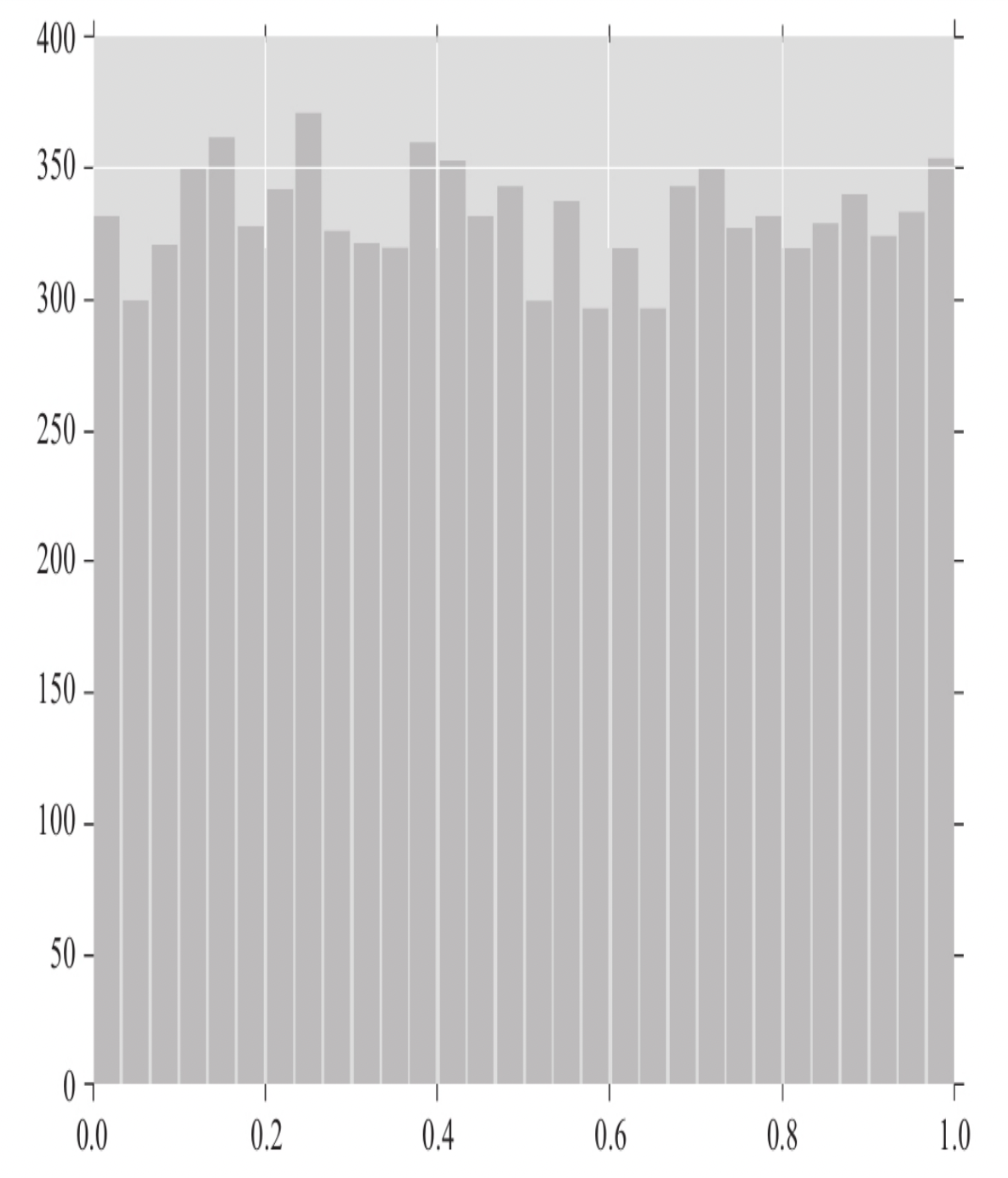
3.1.1.1 rand和random_sample
rand和random_sample都是均匀分布(uniform distribution)的随机数生成函数。(一般来讲,推荐使用random_sample )
1 | import numpy as np |
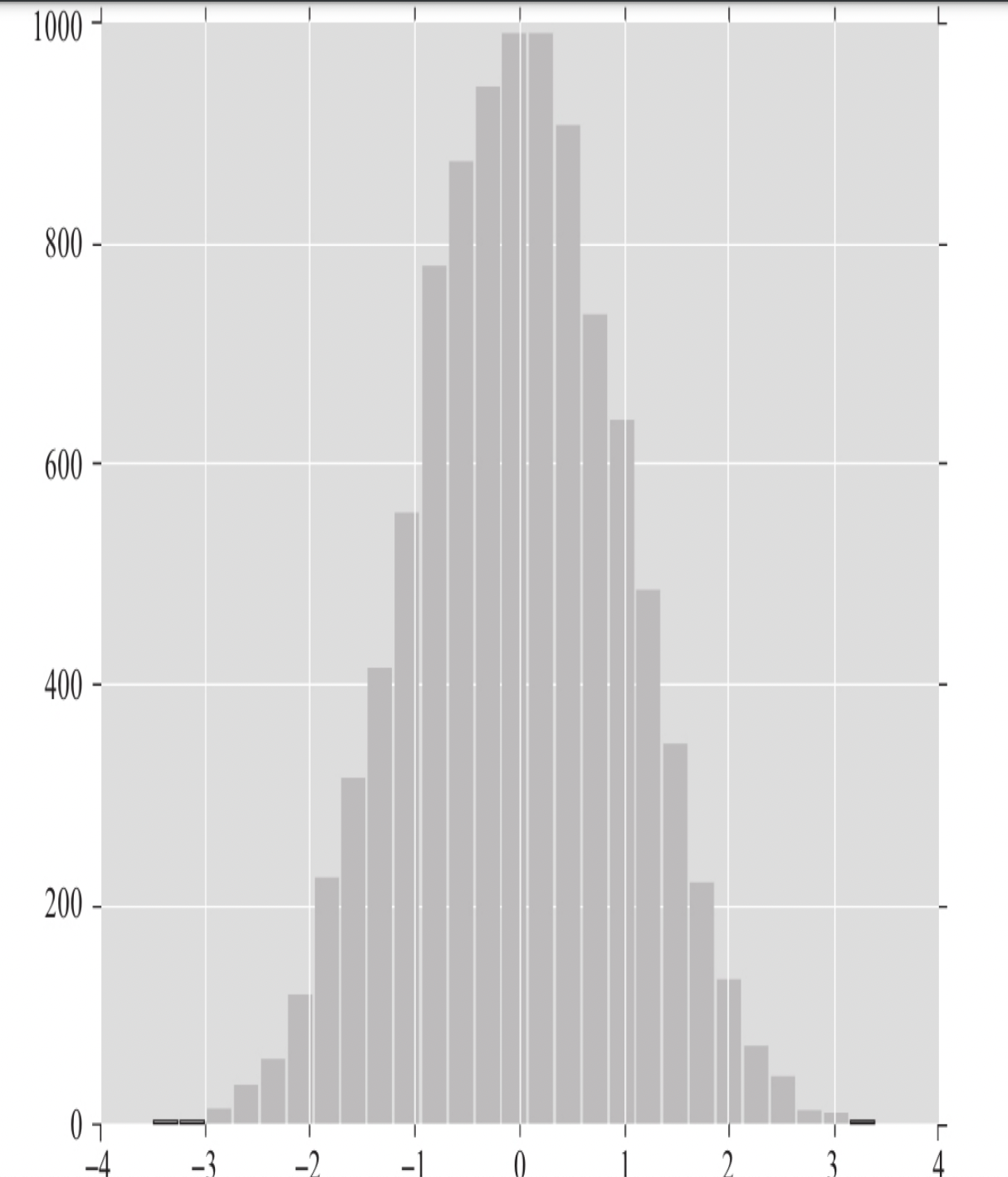
3.1.1.2 randn和standard_normal
randn和standard_normal是正态分布的随机数生成函数。推荐使用standard_normal
1 | import numpy as np |
3.1.1.3 randint和random_integers
randint和random_integers是均匀分布的整数生成函数。
函数需要传入三个参数:
- low (区间的最小值)
- high (区间的最大值)
- size (生成的数组大小) — size是一个n维元组数据
randint和random_integers的区别在于,randint的范围不包括最大值,而 random_integers包括最大值。
1 | x1=np.random.randint(1,10,(100)) |
3.1.1.4 shuffle
shuffle可以随机打乱一个数组,并且改变此数组本身的排列。
1 | x=np.arange(10) |
3.1.1.5 Permutation
Permutation用于返回一个打乱后的数组值,但是并不会改变传入 的参数数组本身
1 | x=np.arange(10) |
3.1.1.6 二项式分布
N次伯努利试验的结果分布即为二项分布。使用binomial(1,p)即为 一次二项分布。使用binomial(1,p,n)即表示生成n维的二项分布数组,也 就是伯努利分布。
1 | import numpy as np |
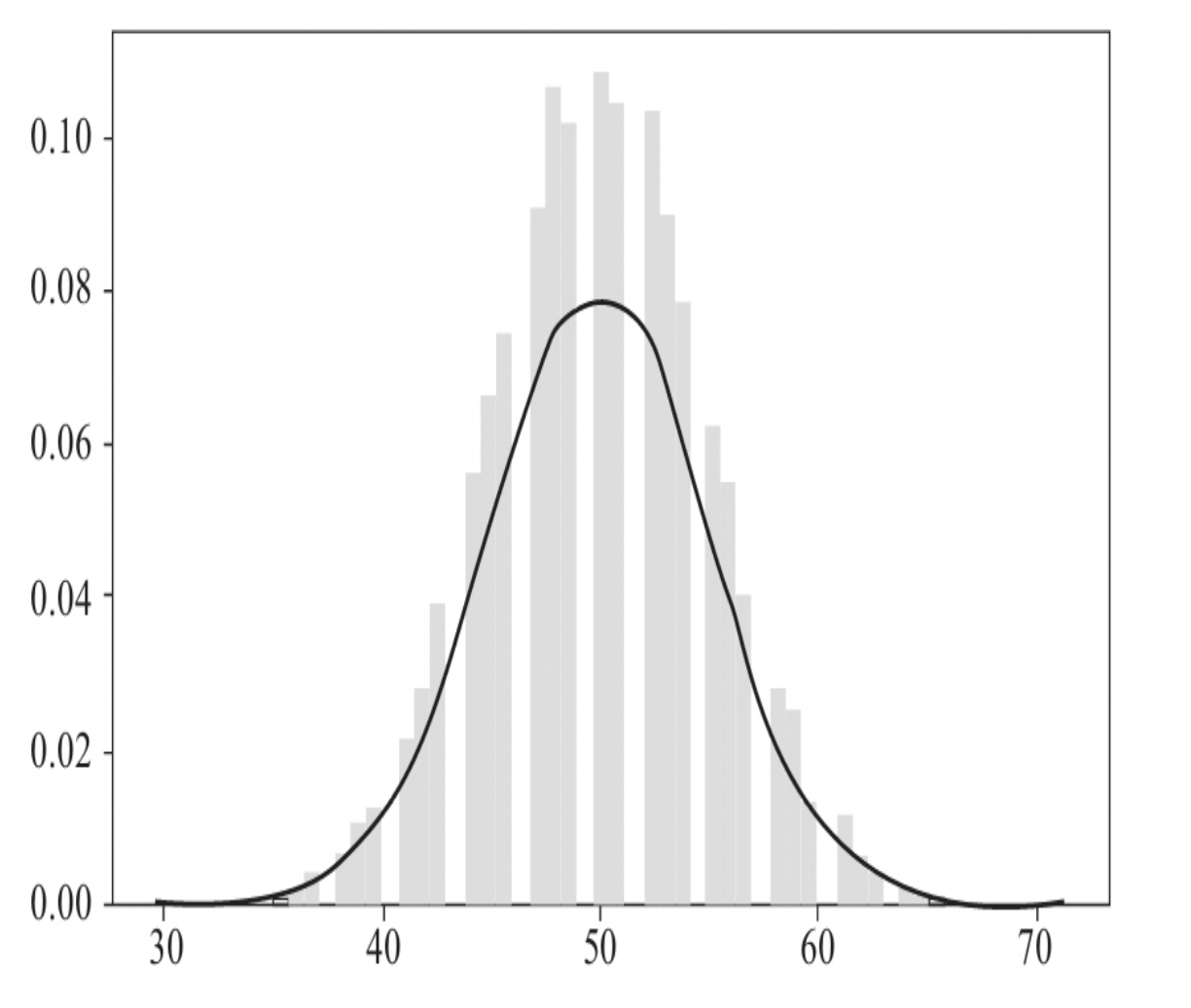
3.1.2 随机数种子
调用
seed(),会根据系统提供的数据进行随机初 始化,也就是每次得到的随机数都会不一样。调用seed(x)的时候,计算机会根据x值进行初始化,如果x值是同一个x值,那么随机得到的结果也是一样的。
1 | np.random.seed() |
3.1.3 相关系数
数学相关,暂放
3.1.4 基本统计量
下面就来介绍一些常用的统计量,所谓统计量,就是利用数据的 函数变化,从某种维度来反映全体数据集的特征的一种函数。
3.1.4.1 mean
mean函数可用于计算数组的平均值。函数的第二个参数可以用来 选择不同的维度进行计算。
1 | x=arange(20) |

